Azure IoT, Streaming Analytics, Data Lake Analytics and JSON
Overview
As part of the work developing and designing content for the Azure IoT MPP I explored how to connect device telemetry from an IoT Hub to Data Lake Analytics for some big-data analysis. It turns out that it is not quite as straightforward as I had imagined. I was unable to directly connect the IoT Hub to Data Lake Storage Gen 1 so I had to add Azure Streaming Analytics to the solution:
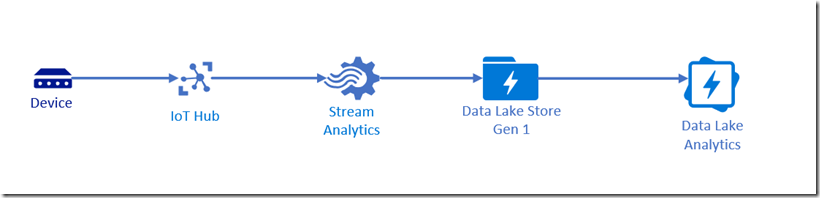
Key issues I encountered include:
- Azure IoT Hub supports routing messages direct to Azure Blob Storage, but not Data Lake Storage, requiring the addition of Azure Streaming Analytics to the solution architecture.
- The device telemetry is usually passed as JSON from the device through the IoT Hub - this is handled nicely by Azure Streaming Analytics queries, however JSON support is not yet built-in to Data Lake Analytics
- The output to Data Lake Storage in Azure Streaming Analytics (ASA) defaults to CSV - this does not do a good job storing your JSON telemetry.
- Switching the data lake output in ASA to JSON writes each row as a separate JSON object by default, resulting in an output file that is actually invalid JSON - switching the Format from Line separated to Array addresses this.
- In order to handle JSON with Data Lake Analytics U-SQL jobs, two .NET assemblies must be registered within a database stored in Data Lake Storage - this makes available a Json Extractor as well as some supporting JSON functions.
Configuring the Solution
My experimental solution has a pretty straightforward configuration.
IoT Hub
The IoT Hub is using the S1 configuration and I used the MXChip AZ3166 Devkit connected via a Device Connection String provisioned on the IoT Hub.
The IoT Hub message routing is configured as follows:
- Endpoint: the built-in events endpoint
- Data source: Device Telemetry Messages
- Routing query: true (as the routing query is an expression that evaluates to true or false for each received message, the simplest way to send all messages to the endpoint is to just supply true as the query).
Note: As this matches all messages for the $Default consumer group, you will need to add another consumer group to the IoT Hub if you wish to also send messages elsewhere from the IoT Hub. You can learn more about Consumer Groups here.
The message format routed from the IoT Hub looks like this:
{
"metadata":
{
"deviceType": "WeatherStation",
},
"telemetry":
{
"temperature": 23.700001,
"pressure": 814.361084,
"humidity": 23.9,
"windSpeed": 12.599993,
"windDirection": 22
},
"EventProcessedUtcTime": "2019-01-26T22:38:35.6944102Z",
"PartitionId": 1,
"EventEnqueuedUtcTime": "2019-01-26T22:37:23.3830000Z",
"IoTHub":
{
"MessageId": null,
"CorrelationId": null,
"ConnectionDeviceId": "CWF-MX-001",
"ConnectionDeviceGenerationId": "636819084296189295",
"EnqueuedTime": "2019-01-26T22:37:23.1800000Z",
"StreamId": null
}
}
Data Lake Storage
As Azure Streaming Analytics currently only supports Gen1 of the Data Lake Storage, I made sure to create the correct type. Nothing special in the creation of this resource - I chose Pay-as-You-Go
Azure Streaming Analytics
In order to connect the IoT Hub telemetry to the Data Lake Storage, I had to provision Azure Streaming Analytics and create one input, one output and setup a query.
Inputs
I added a Stream Input, choose IoT Hub and then used the option to Select IoT Hub from your subscriptions. Things to note:
- Input alias: IoTHubInput
- Endpoint: Messaging
- Consumer group: $Default (you may have chosen to create a new, dedicated consumer group)
- Event serialization format: JSON
Outputs
I added a Data Lake Storage Gen1 output and then used the option to Select Data Lake Storage Gen1 from your subscriptions. Things to note:
- Input alias: DataLakeOutput
- Path prefix pattern: telemetry/{date}
- Date format: YYY/MM/DD
- Event serialization format: JSON
- Format: Array (this dramatically simplifies the U-SQL in Data Lake Analytics)
You also need to authorize the connection to the Data Lake Storage Gen1 account.
Query
The ASA query is pretty straightforward:
SELECT
*
INTO
[DataLakeOutput]
FROM
[IoTHubInput]
WHERE
METADATA.deviceType = 'WeatherStation';
Note: The where clause can leverage nested properties in the JSON telemetry message.
Running this ASA job and streaming telemetry from the device will start messages being sent to the Data Lake Storage. If you use the Data Explorer, you will see that the telemetry folder is created, with a nested folder created for the year, i.e. 2019, which then contains a folder for the month, i.e. 01, which then contains one or more files. Each file starts with a two character day, i.e. 26_ and then time and a GUID and has the JSON file extension:
- [Your Data Lake Storage Name]
- telemetry
- 2019
- 01
- 26_0_314640be979644a3bf58346413df7f7b.json
- 01
- 2019
- telemetry
Note: If you select the file, you will see a view of the data, however the viewer assumes that the data is CSV, so the JSON will be split into columns... A simple workaround here is to choose Format, change the Delimiter to Custom and then enter something unlikely to occur in the data such as *.
Data Lake Analytics
So far, there hasn't been anything too surprising (aside from the default JSON format). However, it was here that I was surprised to discover that JSON is not one of the built-in formats handled by Data Lake Analytics. That said, some searches showed that Microsoft built the platform to be extensible and have a GitHub repository that hosts examples for U-SQL as well as assemblies that provide support for the following formats:
- AVRO
- JSON
- XML
You will need to build these assemblies and then register them within your Data Lake Analytics environment.
Custom JSON Extractor Assemblies
To obtain the custom JSON assemblies:
- Clone the U-SQL repository from GitHub.
- In Visual Studio, open the Microsoft.Analytics.Samples.Formats project (under the
<PathYouSelected>\usql\Examples\DataFormatsfolder). - Build the project in Visual Studio in Release mode.
- Locate these two DLLs in the
<PathYouSelected>\usql\Examples\DataFormats\Microsoft.Analytics.Samples.Formats\bin\Releasefolder- Microsoft.Analytics.Samples.Formats.dll
- Newtonsoft.Json.dll
We will be copying these files into Data Lake Analytics shortly.
Create a Database in Azure Data Lake
A database is required as the assemblies have to be registered into a database and using Master for this purpose isn't ideal. Create and run the following U-SQL job:
CREATE DATABASE IF NOT EXISTS MyJsonDb;
Register Custom JSON Assemblies in Azure Data Lake
Upload your two DLLs from the bin folder above to your desired location in Azure Data Lake Store. You'll need to create a folder for them first. I used the following path: \Assemblies\JSON at the root of my storage.
Note: Don't forget to specify relevant security on the new Assemblies folder so your users are able to reference the assemblies when needed.
Now that the files are somewhere Azure Data Lake Analytics (ADLA) can find, we want to register the assemblies. Create and submit a new U-SQL job:
USE DATABASE [MyJsonDb];
CREATE ASSEMBLY [Newtonsoft.Json] FROM @"/Assemblies/JSON/Newtonsoft.Json.dll";
CREATE ASSEMBLY [Microsoft.Analytics.Samples.Formats] FROM @"/Assemblies/JSON/Microsoft.Analytics.Samples.Formats.dll";
If you now browse under MyJsonDb database in the Data Explorer in Data Lake Analytics, you should see the two assemblies are now listed under Assemblies.
Now we have these assemblies registered, how can we use them?
Extracting and Selecting JSON in Data Lake Analytics
As mentioned earlier, a single telemetry record looks like:
{
"metadata":
{
"deviceType": "WeatherStation",
"studentId": "ABCDEFGHIJK",
"uid": "090349F9"
},
"telemetry":
{
"temperature": 23.700001,
"pressure": 814.361084,
"humidity": 23.9,
"windSpeed": 12.599993,
"windDirection": 22
},
"EventProcessedUtcTime": "2019-01-26T22:38:35.6944102Z",
"PartitionId": 1,
"EventEnqueuedUtcTime": "2019-01-26T22:37:23.3830000Z",
"IoTHub":
{
"MessageId": null,
"CorrelationId": null,
"ConnectionDeviceId": "CWF-MX-001",
"ConnectionDeviceGenerationId": "636819084296189295",
"EnqueuedTime": "2019-01-26T22:37:23.1800000Z",
"StreamId": null
}
}
For the purposes of this exercise, we want to read the JSON and output a CSV formatted like:
>"date","EventProcessedUtcTime","PartitionId","EventEnqueuedUtcTime","metadata_deviceType",,"telemetry_temperature","telemetry_pressure","telemetry_humidity","telemetry_windSpeed","telemetry_windDirection","IoTHub_ConnectionDeviceId"
2019-01-26T00:00:00.0000000,2019-01-26T22:38:35.2033673Z,1,2019-01-26T22:37:18.0540000Z,"WeatherStation",23.700001,814.300537,24,12.599993,16,"CWF-MX-001"
2019-01-26T00:00:00.0000000,2019-01-26T22:38:35.6944102Z,1,2019-01-26T22:37:23.3830000Z,"WeatherStation",23.700001,814.361084,23.9,12.599993,22,"CWF-MX-001"
Or in tabular form:
| date | EventProcessedUtcTime | PartitionId | EventEnqueuedUtcTime | metadata_deviceType | telemetry_temperature | telemetry_pressure | telemetry_humidity | telemetry_windSpeed | telemetry_windDirection | IoTHub_ConnectionDeviceId |
|---|---|---|---|---|---|---|---|---|---|---|
| 2019-01-26T00:00:00.0000000 | 2019-01-26T22:38:35.2033673Z | 1 | 2019-01-26T22:37:18.0540000Z | WeatherStation | 23.700001 | 814.300537 | 24 | 12.599993 | 16 | CWF-MX-001 |
| 2019-01-26T00:00:00.0000000 | 2019-01-26T22:38:35.6944102Z | 1 | 2019-01-26T22:37:23.3830000Z | WeatherStation | 23.700001 | 814.361084 | 23.9 | 12.599993 | 22 | CWF-MX-001 |
The actual JSON stored in the Data Lake Storage is formatted like this:
[{"metadata":{"deviceType":"WeatherStation"},"telemetry":{"temperature":23.700001,"pressure":814.300537,"humidity":24,"windSpeed":12.599993,"windDirection":16},"EventProcessedUtcTime":"2019-01-26T22:38:35.2033673Z","PartitionId":1,"EventEnqueuedUtcTime":"2019-01-26T22:37:18.0540000Z","IoTHub":{"MessageId":null,"CorrelationId":null,"ConnectionDeviceId":"CWF-MX-001","ConnectionDeviceGenerationId":"636819084296189295","EnqueuedTime":"2019-01-26T22:37:17.9290000Z","StreamId":null}},
{"metadata":{"deviceType":"WeatherStation"},"telemetry":{"temperature":23.700001,"pressure":814.361084,"humidity":23.9,"windSpeed":12.599993,"windDirection":22},"EventProcessedUtcTime":"2019-01-26T22:38:35.6944102Z","PartitionId":1,"EventEnqueuedUtcTime":"2019-01-26T22:37:23.3830000Z","IoTHub":{"MessageId":null,"CorrelationId":null,"ConnectionDeviceId":"CWF-MX-001","ConnectionDeviceGenerationId":"636819084296189295","EnqueuedTime":"2019-01-26T22:37:23.1800000Z","StreamId":null}}]
To process this into the desired CSV output, we will need to create and run a U-SQL job like this:
REFERENCE ASSEMBLY MyJsonDb.[Newtonsoft.Json];
REFERENCE ASSEMBLY MyJsonDb.[Microsoft.Analytics.Samples.Formats];
USING Microsoft.Analytics.Samples.Formats.Json;
// Create a fileset and create a virtual field, date, from the name of the directories and the first two
// characters of the filename
DECLARE @InputPath string = "/telemetry/{date:yyyy}/{date:MM}/{date:dd}_{*}.json";
DECLARE @OutputFile string = "/output/weatherstationresults.csv";
@json =
EXTRACT
date DateTime,
EventProcessedUtcTime DateTime,
PartitionId int,
EventEnqueuedUtcTime DateTime,
metadata_deviceType string,
telemetry_temperature double,
telemetry_pressure double,
telemetry_humidity double,
telemetry_windSpeed double,
telemetry_windDirection double,
IoTHub_ConnectionDeviceId string
FROM
@InputPath
USING new MultiLevelJsonExtractor(null,
true,
"EventProcessedUtcTime",
"PartitionId",
"EventEnqueuedUtcTime",
"metadata.uid",
"telemetry.temperature",
"telemetry.pressure",
"telemetry.humidity",
"telemetry.windSpeed",
"telemetry.windDirection",
"IoTHub.ConnectionDeviceId"
);
OUTPUT @json
TO @OutputFile
USING Outputters.Csv(outputHeader:true);
There are a few interesting things in this U-SQL. Firstly, the references:
REFERENCE ASSEMBLY MyJsonDb.[Newtonsoft.Json];
REFERENCE ASSEMBLY MyJsonDb.[Microsoft.Analytics.Samples.Formats];
This allows us to access the capability of these assemblies in the U-SQL.
Next, we use a new extractor - MultiLevelJsonExtractor. This extractor allows the use of the JSON dot notation to access nested properties. From the comments in the source for this class:
/// <summary>
/// Use it by supplying multiple levels of Json Paths. They will be assigned to the schema by index.
/// </summary>
/// <param name="rowpath">The base path to start from.</param>
/// <param name="bypassWarning">If you want an error when a path isn't found leave as false. If you don't want errors and a null result, set to true.</param>
/// <param name="jsonPaths">Paths in the Json Document. If it isn't found at the "rowpath" level it will recurse to the top of the tree to locate it.</param>
public MultiLevelJsonExtractor(string rowpath = null, bool bypassWarning = false, params string[] jsonPaths)
: base(rowpath)
If you are familiar with U-SQL, the rest of the script is pretty straight forward.
But, what if we had left the default JSON output format to Line separated instead of changing it to Array. Well, then we've created more work, but we can still process the JSON. Consider the following U-SQL:
REFERENCE ASSEMBLY MyJsonDb.[Newtonsoft.Json];
REFERENCE ASSEMBLY MyJsonDb.[Microsoft.Analytics.Samples.Formats];
USING Microsoft.Analytics.Samples.Formats.Json;
// Create a fileset and create a virtual field, date, from the name of the directories and the first two
// characters of the filenameDECLARE @InputPath string = "/telemetry/{date:yyyy}/{date:MM}/{date:dd}_{*}.json";
DECLARE @OutputFile string = "/output/weatherstationresults.csv";
// First we need to get each row as a string
@jsonStrings =
EXTRACT
date DateTime,
jsonString string
FROM
@InputPath
USING Extractors.Tsv(quoting:false);
// Now break the top-level json into tuples
@jsonTuples =
SELECT
date,
JsonFunctions.JsonTuple(jsonString) AS toplevel
FROM
@jsonStrings;
// now process the next level json into tuples
@nextLevelJson =
SELECT
date AS record_date,
toplevel["EventProcessedUtcTime"] AS eventProcessedUtcTime,
toplevel["PartitionId"] AS partitionId,
toplevel["EventEnqueuedUtcTime"] AS eventEnqueuedUtcTime,
JsonFunctions.JsonTuple(toplevel["metadata"]) AS metadata,
JsonFunctions.JsonTuple(toplevel["telemetry"]) AS telemetry,
JsonFunctions.JsonTuple(toplevel["IoTHub"]) AS IoTHub
FROM
@jsonTuples;
// now extract all the values we need
@finalJson =
SELECT
record_date,
eventProcessedUtcTime,
partitionId,
eventEnqueuedUtcTime,
metadata["deviceType"] AS metadata_deviceType,
telemetry["temperature"] AS telemetry_temperature,
telemetry["pressure"] AS telemetry_pressure,
telemetry["humidity"] AS telemetry_humidity,
telemetry["windSpeed"] AS telemetry_windSpeed,
telemetry["windDirection"] AS telemetry_windDirection,
IoTHub["ConnectionDeviceId"] AS telemetry_ConnectionDeviceId
FROM
@nextLevelJson;
OUTPUT @finalJson
TO @OutputFile
USING Outputters.Csv(outputHeader:true);
This requires significant manipulation to be able to process the records. Effectively the flow is:
- Separate each row of the input into a string
- Break the top-level properties into tuples using the
JsonFunctions.JsonTupleUser Defined Function (UDF) that is defined in theMicrosoft.Analytics.Samples.Formatsassembly. Note how we access a the key/value pair:toplevel["EventProcessedUtcTime"] AS eventProcessedUtcTime - Process the next level properties into tuples using a similar process to the step above.
- Process the final results into a flat structure
- Output to CSV.
I think you'll agree - outputting as an Array simplifies the process. Of course, this is a straightforward example of writing the flattened data out to a CSV - you can still perform other aggregate operations as usual.
Summary
In this post I recorded some of what I have learnt integrating Data Lake Analytics into Azure IoT and, more specifically, how I can work with JSON telemetry data. I hope you find this useful.